The need for lower latencies and higher bandwidths has pushed the use of FPGAs into more and more compute applications across many different markets and domains. With this increased demand comes challenges of balancing the performance and economics of FPGA usage, thus driving the need to do more processing with less fabric. This drive to squeeze as much performance out of as few logic gates as possible can be a recipe for disaster if the appropriate architectural and system considerations aren’t addressed early in a new design effort.
In modern FPGA designs, achieving high clock frequencies and wide data paths are often essential to meet complex interface and intensive processing requirements. However, as fabric utilization increases, even meticulously architected designs can struggle to achieve timing closure. This challenge can lead to extended build times, inconsistent performance, and project delays. In this blog, we’ll explore the technical aspects of logic congestion in FPGAs and describe effective strategies for mitigation.
Understanding how performance parameters affect timing closure is critical in synchronous FPGA designs:
– Clock Frequency: In a synchronous design, logic functions, such as Look-Up Tables (LUTs) and multiplexers, receive clocked inputs and drive registered outputs. Typically, a logic function must produce a valid output within a single clock period. As clock frequency increases, the logic resolution time is compressed, potentially causing complex, multi-level logic functions to violate setup time requirements and create critical timing paths.
– Data Bus Width: Widening a data bus enables higher data rates at a given clock frequency but can create fabric utilization and timing challenges. Each additional signal increases resource consumption within the FPGA fabric, introduces unique propagation delays through the fabric, and increases burden on the placement engine to converge on a nominal routing path. This variation in arrival times across the bus, known as bus skew, becomes progressively more problematic for data paths with near-zero slack time. Furthermore, unconstrained bus skew can exhibit considerable variation between synthesis and place-and-route iterations.
Let’s examine an FPGA implementing an 8-lane, 64 GT/s PCI-Express Gen3 interface. To meet bandwidth requirements, the fabric operates at 250 MHz with a 256-bit data bus. Twelve incoming ADC data streams, each averaging 4 Gb/sec, time-division multiplex their access to this interface, with sufficient buffering to support round-robin arbitration.
If this design utilizes approximately 60% of the FPGA fabric, then you might observe significantly lengthened build times due to increased placement and routing effort. Furthermore, timing violations may intermittently appear from build to build, often within the converging data paths of the ADC streams. Inconsistent place and route timing results are often a strong indicator of logic congestion, as the tools struggle to produce an optimal solution within the constrained fabric.
Let’s explore specific techniques that target the root causes of timing violations.
Pipelining for Routing Delay Reduction:
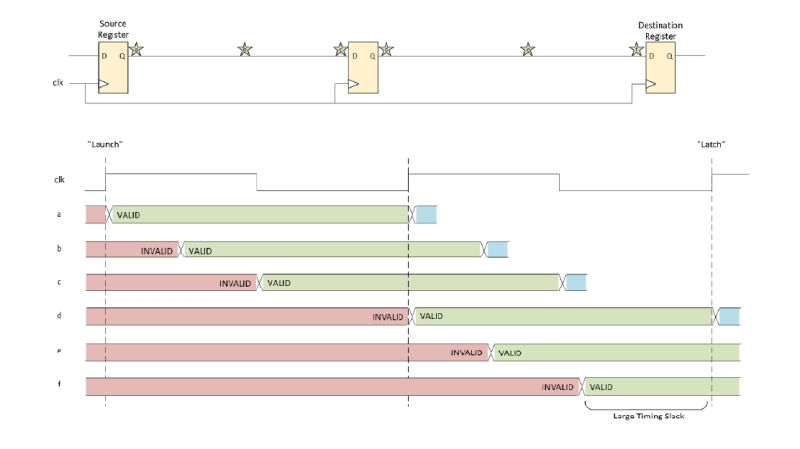
A timed path includes routing and logic elements between the launch (or source) register and the latch (or destination) register. Pipelining involves inserting one or more registers into a timed path to divide it into several separately timed paths. The diagrams below illustrate a simplified example of how pipelining works. The first diagram depicts a prime candidate for pipelining:
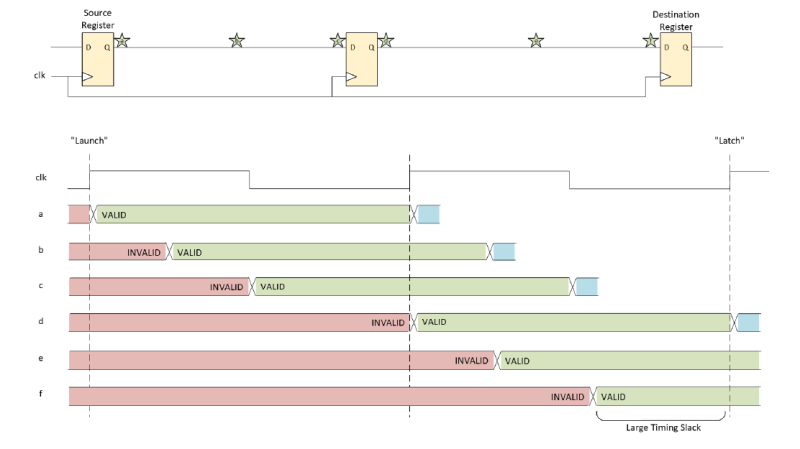
At various points in the path, you can see the propagation delay of the signal launched from the source register. It happens to reach the destination register just in time for the next clock, yielding very little timing slack. By adding a pipeline register in the middle of this path, the timing slack at the destination registers increases dramatically: